Diffusion verses Flow Matching
An accessible introduction to diffusion and flow matching models.
Jul 19, 2023This post is a summary of a couple of generative modeling papers recently that have been impactful. I’m primarily writing this for my own understanding, but hopefully it’s useful to others as well, since this is a fast-paced area of research and it can be hard to dive deeply into each new paper that comes out.
This post uses what I’ll call “math for computer scientists”, meaning there will likely be a lot of abuse of notation and other hand-waving with the goal of conveying the underlying idea more clearly. If there is a mistake (and it looks unintentional) then let me know!
All Papers
This post will discuss three papers:
- Diffusion from Denoising Diffusion Probabilistic Models
- Latent Diffusion from High-Resolution Image Synthesis with Latent Diffusion Models (a.k.a. the Stable Diffusion paper)
- Flow Matching from Flow Matching for Generative Modeling
Other Good References
- What are diffusion models? from Lil’ Log
- Diffusion Models from Scratch from Tony Duan
Application Links
- Diffusion Distillation from Progressive Distillation for Fast Sampling of Distillation Models
- Simple Diffusion from simple diffusion: End-to-end diffusion for high resolution images
- Autoregressive Diffusion from Autoregressive Diffusion Models
- On the Importance of Noise Scheduling for Diffusion Models
- Voicebox from Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
- Collection of Speech Synthesis Papers
These papers overlap and cite each other in various ways.
Diffusion
Diffusion models can be summarized very shortly as:
- Start with a random image.
- Iteratively add noise to the image.
- Train a model to predict some part of the noise that was added.
- Iteratively remove noise from the image by predicting and subtracting it.
Consider Figure 2 from the original paper:

In the above diagram:
- is some noise, typically Gaussian noise
- is the original image
- is called the reverse process, a distribution over the sligtly less noisy image given the current image
- is called the forward process, a Markov chain that adds Gaussian noise to the data
How do we convert a regular image to Gaussian noise?
Let’s assume we have a noisy image and we want to make it slightly noisier (in other words, take a step along the forward process, ). We sample the slightly noisier image from the following distribution:
This can be read as, “sample from a Gaussian distribution with mean and variance .” The matrix is just the identity matrix, so is the variance of the Gaussian noise being added.
Recall that the sum of two Gaussian distributions is also a Gaussian distribution:
It’s also worth noting that multiplying a zero-mean Gaussian by some factor is equivalent to multiplying the variance by :
So we can rewrite the distribution from earlier as:
This is our forward process :
So, to recap, in order to convert a regular image to Gaussian noise, we repeatedly apply the rule to add noise to the image, and will result in a random distribution of noise.
The variances for each step of the update is given by some schedule . The schedule is typically linearly increasing from 0 to 1, so that on the final step when we will sample a completely noisy image from the distribution .
How do you sample in closed form (i.e., without sampling )?
Rather than having to take our original image and run 1 to steps to get a noisy image, we can use the reparametrization trick.
If we start with our original image , we can write the first slightly noisy image as:
We can rewrite this using as:
We can then write as:
This can be extended recursively1, so we can write in closed form as:
It’s common to express the product as a new variable:
Also, the usual notation is to write , giving the final equation for sampling as:
Sampling from and using it to derive is called Monte Carlo sampling. Alternatively, we can use our notation from earlier to specify the closed-form distribution that the sample is drawn from:
How is the model trained?

The main goal of the learning process is to maximize the likelihood of the data after repeatedly applying the reverse process. First, we sample some noise and then we apply the forward process to get :
The diffusion model training process involves training a model which takes and as input and predicts :
We can train the model to minimize the mean squared error between and :
So, the model is predicting the noise between the noisy image and the original image.
How do you sample from the model?
Now that we’ve ironed out the math for the forward process, we need to flip it around to get the reverse process. In other words, given that we have , we need to derive 2. The first step is to apply the chain rule:
We drop the denominator because is constant when we are sampling.
Recall the probability density function for a normal distribution:
We can use this to rewrite as a function of :
Similarly for :
Anyway, somehow if you do some crazy math you can eventually arrive at the equations for the forward process, which are:
where is new noise to add at each step and is the output of the model.
Latent Diffusion
The latent diffusion paper is most notable because it produces high-quality image samples with a relatively simple model. It contains two training phases:
- Autoencoder to learn a lower-dimensional latent representation
- Diffusion model learned in the latent space
The main insight is that learning a diffusion model in the full pixel space is computationally expensive and has a lot of redundancy. Instead, we can first obtain a lower-rank representation of the image, learn a diffusion model on that representation, then use the decoder to reconstruct the image. So gaining insight into the latent diffusion model comes from understanding how this latent space is constructed.
When looking through the latent diffusion repository code, it’s important to remember that a lot of stuff might be in the taming transformers repository.
How is the autoencoder constructed?
The autoencoder is an encoder-decoder trained with perceptual loss and patch-based adversarial loss, which helps ensure that the reconstruction better matches how humans perceive images.
The perceptual loss takes a pre-trained VGG16 model and extracts four sets of features, projects them to a lower-dimensional space, then computes the mean squared error between the features of the original image and the reconstructed image.
The patch-based adversarial loss is a discriminator trained to classify whether a patch of an image is real or fake. The discriminator is trained with a hinge loss, which is a loss function that penalizes the discriminator more for misclassifying real images as fake than fake images as real.
What is the KL divergence penalty?
Besides the reconstruction loss, an additional slight penalty is imposed on the latent representation to make it closer to a normal distribution, in the form of minimizing the KL divergence between the latent distribution and a standard normal distribution. Recalling that the KL divergence between two distributions and is defined as:
The first term is the entropy of a normal distribution and the second term is the cross-entropy between the two distributions, which have the following forms respectively:
We can substitute these into the KL divergence equation to get:
We can rewrite the KL divergence between and as:
Here’s a PyTorch implementation of this, from the latent diffusion repository:
def kl_loss(mean: Tensor, log_var: Tensor) -> Tensor:
# mean, log_var are image tensors with shape [batch_size, channels, height, width]
logvar = torch.clamp(torch, -30.0, 20.0)
var = logvar.exp()
return 0.5 * torch.sum(torch.pow(mean, 2) + var - 1.0 - logvar, dim=[1, 2, 3])
Flow Matching
Flow-based models are another type of generative model which rely on the idea of “invertible transformations”. Suppose you have a function $f(x)$ which can reliably map your data distribution to a standard normal distribution, and is also invertible; then the function $f^{-1}(x)$ can be used to map from points in the standard normal distribution to your data distribution. This is the basic idea behind flow-based models.
Note that the sections that follow are going to feel like a lot of math, but they are a windy path to get to a nice and easy-to-understand comparison with diffusion models, which is: If you write the steps that diffusion models take as an ODE, the line they trace to get to the final point is not straight; why not just make it straight? Neural networks probably like predicting straight lines. See Figure 3 from the flow matching paper below:
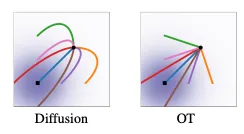
What is a continuous normalizing flow?
Continuous normalizing flows were first introduced in the paper Neural Ordinary Differential Equations. Consider the update rule of a recurrent neural network:
In a vanilla RNN, just does a matrix multiplication on . This can be thought of as a discrete update rule over time. Neural ODEs are the continuous version of this:
The diffusion process described earlier can be conceptualized as a neural ODE - you just have to have an infinite number of infinitesimally small diffusion steps.
This formulation permits us to use any off-the-shelf ODE solver to generate samples from the distribution. The simplest method is to just sample some small and use Euler’s method to solve the ODE (as in the figure below).

How do we train a continuous normalizing flow?
Sampling from an ODE is fine. The real question is how we parameterize these, and what update rule we use to update the parameters.
The goal of the optimization is to make the output of our ODE solver close to our data. This can be formulated as:
To optimize this, we need to know how changes with respect to :
We can use the second equation to move backwards along using another ODE solver, back-propagating the loss at each step.
This function is called the adjoint, and is illustrated in Figure 2 from the original Neural ODE paper, copied below. It’s useful to know about but mainly as a barrier to overcome further down - we don’t want to actually use it because it is computationally expensive to unroll every time we want to update our model.
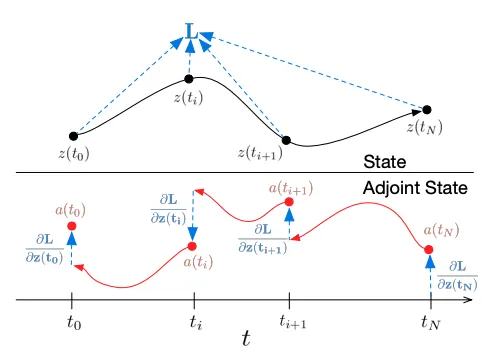
However, the above process can be computationally expensive to do; the analogy in our diffusion model would be having to update every single point along our diffusion trajectory on every update, each time using an ODE solver. Instead, the paper Flow Matching for Generative Modeling proposes a different approach, called Continuous Flow Matching (CFM).
What is continuous flow matching?
First, some terminology: the paper makes use of optimal transport to speed up the training process. This basically just means the most efficient way to move between two points given some constraints. Alternatively, it is the path which minimizes a total cost.
The goal of CFM is to avoid going through the entire ODE solver on every update step. Instead, in order to scale our flow matching model training, we want to be able to sample a single point, and then use optimal transport to move that point to the data distribution.
First, we can express our continuous normalizing flow as a function:
This can be read as, “a function mapping from a point in (i.e., a -dimensional vector) and a time between 0 and 1 to another point in ”. We are interested in the first derivative of the function:
where are the points in the data distribution (for example, our images).
In a CNF, the function , usually called the vector field, is parameterized by the neural network. Our goal is to update the neural network so that we can use it to move from some initial point sampled from a prior distribution to one of the points in our data distribution by using an ODE solver (in other words, by following the vector field).
Some more notation:
- is the prior distribution, usually a standard normal
- is the true data distribution, which is unknown, but we get samples from it in the form of images (for example)
- is the posterior distribution, which we want to be close to
- is the distribution of points at time between and . Think of these as noisy images from somewhere along some path from our prior to posterior distributions.
How do we learn the vector field?
The goal of the learning process, as with most learning processes, is to maximize the likelihood of the data distribution. We can express this using the flow matching objective:
where:
- is the output of the neural network for time and the data sample(s)
- is the “true vector field” (i.e., the vector field that would take us from the prior distribution to the data distribution)
So the loss function is simply doing mean squared error between the neural network output and some “ground truth” vector field value. Seems simple enough, right? The problem is that we don’t really know what and are, since we could take many paths from to .
The insight from this paper starts with the marginal probability path. This should be familiar if you are familiar with graphical models like conditional random fields. The idea is that, given some sample from our data distribution, we can marginalize over all the different ways we could get from to some sample in our data distribution:
This can be read as, “ is the distribution over all the noisy images that can be denoised to an image in our data distribution”.
We can also marginalize over the vector field:
This can be read as, “ is the distribution over all the vector fields that could take us from a noisy image to an image in our data distribution, weighted by the probability of each path that the process would take”.
Rather than computing the (intractable) integrals in the equations above, we can instead condition on a single sample , use that sample to get a noisy sample and then use that noisy sample to compute the direction that our vector field should take to recover the original image , finally minimizing the conditional flow matching objective:
Without going into the math, the paper shows that this objective has the same gradients as the earlier objective, which is a pretty interesting result. It basically means that we can just follow our vector field from the original image to the noisy image, and that vector field is the optimal one to follow backwards to our original image.
The conditional path is chosen to progressively add noise to the sample (this is what diffusion models do):
where:
- is the time-dependent mean of the Gaussian distribution, ranging from (i.e., the prior is has mean 0) to (i.e., the posterior is has mean )
- is the time-dependent standard deviation, ranging from (i.e., the prior has standard deviation 1) to (i.e., the posterior has some very small amount of noise)
Using the above notation, the paper considers the flow:
Remember that is the flow at time for the sample , meaning the point that we would get to if we followed the vector field from for time (in other words, the noisy image).
Recall from earlier that is just the derivative of this field, which gives us a closed form solution for our target values in our objective:
where:
- is the derivative of with respect to
- is the derivative of with respect to
This is basically just a more general formulation of diffusion models. Specifically, diffusion models can be expressed as:
although here is slightly different from earlier.
Alternatively, the optimal transport conditioned vector field can be expressed as:
This vector field linearly scales the mean from the image down to 0, and linearly scales the standard deviation from up to 1. This has the derivatives:
Plugging into the above equation gives us (don’t worry, it’s just basic algebra):
So, to recap the learning procedure:
- Choose a sample from the dataset.
- Compute using the equation above.
- Predict using the neural network.
- Minimize the mean squared error between the two.
Then, sampling from the model is just a matter of following the flow from some random noise vector along the vector field predicted by the neural network, as you would with a regular ODE.
Specifically, they found that they were able to get good quality samples using a fixed-step ODE solver (the simplest kind) using steps.