Consumer Humanoids
📋 Summary
- Humanoid hardware has commoditized - as of a couple weeks ago, you can buy a humanoid for less than an iPhone, but few people have realized this yet and no one has figured out how to sell millions of them
- Speech-to-speech AI is the wedge - build a viral conversational experience first - like Sesame AI is doing for smart glasses - then lock users in with hardware
- Works better for robots than wearables - no social awkwardness, bigger batteries enable better on-device AI, more natural "companion" experience
- The technical moat - speech-to-speech models (not ASR/LLM/TTS) create natural interactions that align with why people want "humanoid" robots
- Path to market - white-label hardware (Noetix or Joytech), focus on speech model, sell 100 units to validate
It's been an interesting experience over the last few months to start winding down K-Scale, but as I've had more time to exercise and mediate recently I've come to accept that the idea had basically run it's course. For people who aren't familiar with what we were doing, here's my original pitch for the company. The goal was to leverage being open-source to quickly and cheaply get our robot into developer hands so we could start upselling high-margin software. We never really got around to the second part - the first part was pretty ambitious, particularly for someone who didn't even know how to CAD going into it.
It's a bit wild to reflect on how much has happened in less than two years. When I started K-Scale, the Unitree G1 hadn't even come out.1 Today, you can buy a humanoid robot on JD.com for less than the cost of an iPhone, and I personally know at least three other Chinese companies planning to release comparable products in the next few months. The commoditization and price competition is already happening, absent K-Scale's involvement.
I'm still quite obsessed with the idea of building a consumer humanoid company. I'm strongly convinced that humanoids will be the next billion-device platform, and there will be a few generational humanoid companies that get built over the next few years. On top of that, I don't think anyone is currently poised as an obvious winner. The best-funded robotics companies in the United States are thinking about general-purpose robots through the lens of conventional robotics businesses - trying to make a robot that can do everything - which seems to me to still be pretty far away, like self-driving in 2018. No one has cracked the code for selling millions of humanoids yet, and the dynamics that led to DJI becoming dominant in drones or Apple becoming dominant in smartphones don't seem to be present yet for humanoids.
I've been ruminating a lot over one particular idea that seems really promising, and I wanted to expand on it more in a blog post so that I can see what other people might think about it.
The wedge: Speech-to-speech AI
There's a recent YC company called Lightberry which pitched itself as building speech models for robots, but has since expanded their pitch to be cross-embodiment robot brains. I think that pivot is probably a mistake, not simply because it positions them as a Skild or Physical Intelligence competitor, but because "speech models for robots" is actually a pretty good wedge into building a consumer humanoid company.
The Sesame playbook
Right after I left Meta and before I started K-Scale, I got an offer to join Sesame AI as a cofounder and Head of ML. I actually accepted the offer when I got it (before somewhat shamefully renegging to do my own startup), but I was very excited about the company at the time, and am very bullish on them today. If you're not familiar with Sesame, they're building AI-powered smart glasses, and are the creators of this viral speech assistant (which has spawned a very interesting subreddit).
What I liked about Sesame was how the team was thinking about AI-powered consumer products. At the time, there were a number of hit consumer AI models, like Midjourney and Character AI, that had been able to tap into unprecedented consumer interest in trying out weird and novel AI experiences. The downside for those models was that although they could rapidly scale to lots and lots of people, and in some cases throw off a ton of cash, they didn't seem very sticky or robust to competition from hyperscalers or the open-source community.
It was pretty clear to me that there was going to be a similar conversational voice product built on some of the speech-to-speech research that I had been tangentially involved in. Sesame's approach of building the voice assistant into a pair of glasses seemed like a very good way to solve the stickiness problem - you buy the glasses so you can talk to the cool AI assistant, but once you have them, the switching cost to some other conversational agent becomes pretty high. If you can get the AI assistant to actually start doing useful stuff, and maybe integrate it with the user's personal data or some other high-value workflow, you could see how it could go from an AI novelty to a really powerful consumer product. Most importantly, being able to build an AI voice agent independently of a hardware product would be a great way to derisk a Humane-style implosion - you figure out how to make a consumer experience that people love first, then ship hardware to lock them into that experience forever after it's good.
Why speech-to-speech matters
Sesame recruited me because I co-authored some relevant work, most prominently a paper called HuBERT. The original research problem we were investigating with HuBERT was simplifying representation learning for low-resource ASR. Prior contrastive methods were very finicky to train due to issues like mode collapse, whereas the approach in HuBERT was relatively robust, despite involving some non-intuitive representation learning tricks.2
After we published it, there were a number of follow-up works which showed that HuBERT actually worked pretty well as a prosidy-preserving semantic tokenizer. That led in a few interesting directions - one was the Textless NLP work, which was a precursor for a lot of the generative conversational voice tools you see today from startups like Sesame and Kyutai. Another direction was voice changing:
To understand what Sesame did well to make their voice agent sound so engaging and natural, it's helpful to reference Figure 2 from a recent survey paper When Large Language Models Meet Speech: A Survey on Integration Approaches. For a few years, the "Audio-token-based" branch has been a dream for researchers, but it hasn't worked that well because of the lack of high-quality conversational speech data. For a while, the closest thing that worked here is audio token generation, because you could finetune an LLM on Librilight (large dataset of audiobooks). When you talk to conversational agents built using techniques from the other branches, they don't pass the Turing test - it's like talking to someone who is reading you answers from a book. Being able to directly model audio (combined with a sufficiently large and high-quality audio dataset) unlocks the ability to build really great, natural-sounding conversational AI models.

Why this works better for humanoids
I basically think the Sesame go-to-market strategy wouldn't just work for humanoids, it would probably work better.
The wearables problem
For one, I think the adoption for voice assistants that you wear on your body is a pretty high-friction experience and always will be. When you're walking around in public, it's a bit weird to talk to your assistant when other people are around - a lot of people relish the privacy of being able to interact through your phone. In contrast, no one will give you a hard time if you talk to a robot.
For another, with wearables, you're always fighting to reduce weight and heat while preserving 24-hour battery life, which is a hard set of constraints to work around if you want to build a really great AI experience. Assuming you don't want your customers to carry around hot bricks everywhere they go, this means that any voice AI model you build will likely needs to run mostly in the cloud, which I personally think really hurts the experience for on-the-go speech models. You end up fighting with lag, audio compression, network drops, and other annoying things that pull you away from the "in person" experience that I think you would want. In contrast, humanoids have big batteries on them, and they won't complain about having to wear a backpack with a heatsink on it.
Market validation
Is there actually a niche for speech-to-speech models in robotics, where they can provide a meaningfully better experience than the standard ASR / LLM / TTS stack that everyone uses today? After having talked to a lot of robotics early adopters, I think there is. Many of our prospective customers at K-Scale had come up with names for their future robot companions, and seemed quite attached to the "human" part of humanoid robots. K-Scale's initial virality was driven mostly by our first prototype, Stompy, which we intentionally designed to look very friendly, in contrast to the more industrial look and feel of other humanoids - I think this struck a chord with a lot of people who couldn't imagine a black-faced Optimus cleaning up after their kids, and my intuition (backed up by some early commercial data) is that this ICP is bigger than most people would appreciate.

Another datapoint: when the CEO of Joytech was raising money for his company to start mass-producing the Zeroth Bot, he made a big deal to his potential investors about on-device speech-to-speech models (despite the fact that he himself was essentially a marketing executive who had no idea about how to build them). ByteDance in particular was pretty impressed by these claims and put a check into his company more or less to see if he would deliver on them. So there are some more experienced product marketing folks who are thinking along the same lines as me.
Building the MVP
Ok, so suppose the goal is to sell 100 humanoids to consumers as quickly as possible. Here's my current working model of what it will take to build an MVP.
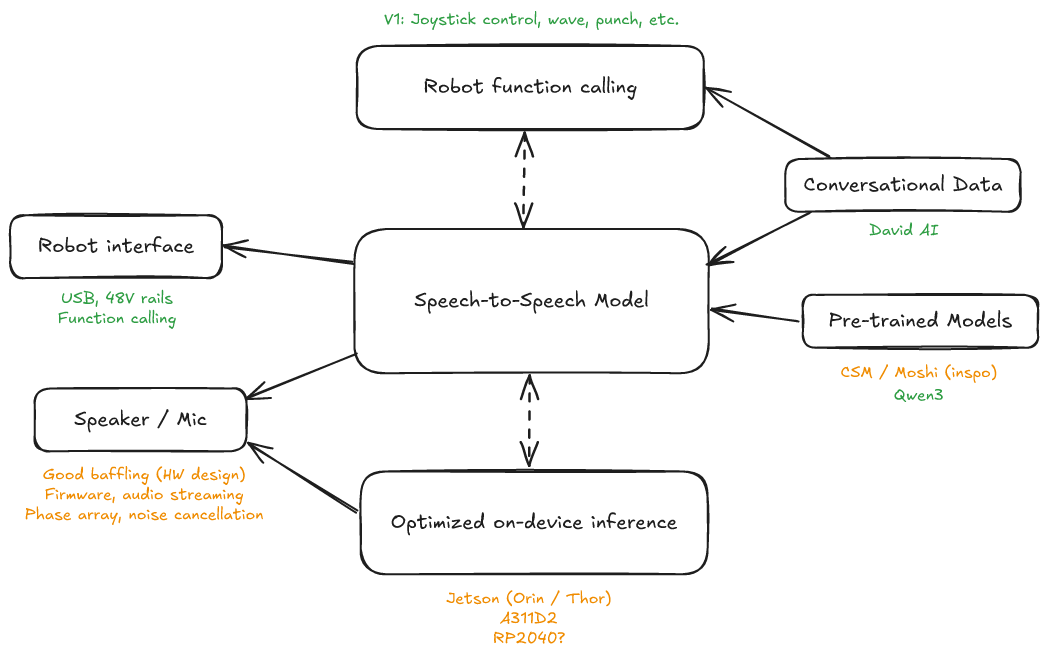
The biggest long-term technical question to me right now is how to make the leap from building a great speech model into building a great robot model - just having your speech model do some simple tool calling on top of a VLA feels suboptimal. I think this will become clearer in the next couple of years. Right now a lot of people in robotics are experimenting with different variants of VLAs and other end-to-end models, and it seems pretty natural to just slot in speech as a modality. But from having talked to a number of customers, I genuinely don't think this is that important of a chasm to cross at this stage for a robot that can be priced somewhere around $4000. At that price point, a cool robot with a fun-to-use voice assistant is more than enough for most people.
Hardware
The riskiest part of getting this thing to market today is clearly the speech model, not the hardware. The rest of the stack is now pretty much commoditized - you can basically just buy white labeled Noetix robots (I recently put in a purchase order for 25) and I know enough Noetix competitors, like Joytech, that it should be easy to second-source a similar robot if there are procurement issues. So supposing we have a good speech model today, I think it would be relatively easy to either slap it onto a white-labeled robot and sell that it a branded product.3
"Slapping it onto a white-labeled robot" would likely entail taking a Jetson, finding a speaker and microphone with decent sound quality (we had a few that we liked at K-Scale), design some enclosure that provides proper baffeling, and hooking up the power and data lines to the Noetix control board. This wouldn't be trivial, but it should be pretty straightforward to get an ODM to do most of this for me if I can guarantee a decently-large purchase order. It might even be possible to get that ODM to do all the assembly and testing in China, if I just provide them with an OS image.
It's an open question about whether or not it makes sense to do this before or after the speech model is ready. I think it makes sense to get started before, since the lead time is pretty long. Noetix has a pretty big backlog for their orders right now and I'd want to get the ball rolling soon. I could probably get a one-off to demo pretty quickly though.
Speech-to-Speech Model
It is trivially easy to put together an MVP of this idea today by gluing together speech APIs, hence companies like Lightberry. There were more than a couple teams who put together this exact demo at K-Scale hackathons. I don't think I would be able to sell the robot like this, but it would let me test out the microphone and speaker quality and provide an integration test for Noetix.
I might be able to license Cartesia's model which would help me shortcut some effort, but I'm not sure what kind of terms I would get on it. When I talked to their CEO a few months ago about having access to one of their model for doing on on-device inference he seemed very reluctant.
There are a few places which might release decent open-source speech-to-speech models that could shortcut some of the effort to train one myself. I personally expect that the big labs won't release open weights speech-to-speech models for the time being, because it's still somewhat sensitive, but you never know.
- CSM (from Sesame). Their open-source model is very nerfed, but could provide a baseline for implementing the rest of the stack on-device before I can finish training a better one.
- MOSS-TTSD seems pretty cool. Definitely an effort to watch.
- Moshi has a decent start but their data seems a lot worse than Sesame's and the agent sounds kind of wonky when you talk to it. Still, a bunch of the Moshi team came from Google and Meta's speech groups and they probably think about the problem in a similar way that I do. In fact, I could probably just ask Eugene to chat about what he's been up to lately, to see if I'm missing something. If I'm gonna do better than them it will be by leveraging better data.
I would like to start with a much larger base model. The issue with most of these models is that they use a lightweight backbone, but I think I can probably heavily quantize a much bigger model and make it run quickly enough to provide real-time audio. That or come up with some kind of cross-attention mechanism so the bigger model can act in the background.
Data
Personally, I think the main reason that Sesame's model was so good is that they were able to get access to particularly high-quality data, specifically from David AI.
Funnily enough, but K-Scale was actually David AI's first customer. The founders approached me during their YC batch to talk about collecting data for robots, and I told them that was a stupid idea, and that they should instead go collect a bunch of two-player speech data so that I could train a good speech-to-speech model. They ended up scraping some bad data from the internet (podcasts and such), and I didn't end up using it, but I did connect me with a bunch of people that I knew from various labs, including Sesame. They have since had a huge amount of success with collecting and selling this type of data. I think I could probably work out some kind of deal with them to give me a decent conversational speech dataset to fine-tune on.
Looking ahead: Made in America?
The scaled version of this idea probably involves manufacturing the robot in America. This was one of my personal ambitions with K-Scale. I don't really like the mechanics of trying to coordinate a bunch of overseas manufacturers to build a great product, even though that's kind of the only way you can operate right now, assuming you're not Tesla-scale. I'm too much of an engineer. The creativity and pace of iteration was much higher when we were hacking on things with our own hands, using 3D printers in our garage, than when we were trying to coordinate a bunch of suppliers.
I'm pretty optimistic that it will be possible to secure relatively-good American-made actuators from an OEM in a few years. One of the coolest things to watch from the last few years is how many people have jumped into designing and building actuators, and sharing learnings and best practices. It's fundamentally not that hard to build a good humanoid actuator, and a lot of people who have gotten started recently have done so with a focus on automation and mass production from first principles. Most people are starting with drone actuators, since it's a relatively captive market (because of the military), and using that as a launching point into humanoids. It's a muscle that still needs to be built, but I'm confident that if the product category explodes, the market will support a few American actuator OEMs.
Resources and Links
Speech-to-Speech Landscape
| Name | Notes |
|---|---|
| Hume | Expressive TTS / conversational API |
| Sesame | Voice assistant + AR glasses |
| Pipecat | Open-source conversational AI framework |
| Gemini Live | Google's speech-to-speech model |
| AWS Nova Sonic | Amazon's speech-to-speech model |
| OpenAI Realtime | OpenAI's speech-to-speech model |
| Elevenlabs | They do have a speech-to-speech API |
| Cartesia | Sonic voice API |
| Vapi | Voice API platform |
| Retell | Conversational AI platform |
| Qwen | Alibaba's model, lots of people distill from this |
| Meta | Meta Full Duplex (Meta AI app) |
| Silencio | Crypto robot speech data startup |
Relevant Papers
American Actuator Manufacturers
| Name | Notes |
|---|---|
| Tyler Chidester | Formerly lead actuator manufacturing at 1X |
| Western Magnetics Company | A16Z-backed actuator startup |
| Chris Vallone | Indie robot guy that is doing interesting stuff |
| Saturn Robotics | Another indie actuator guy |
| Bimotal | Berkeley-based actuator company |
Footnotes
My decision to build my own robot was basically born from talking to the Unitree sales rep, who quoted me almost $90k for the H1 - I thought I could build my own for a lot less money. ↩
This was particularly top-of-mind when thinking about scaling to lots and lots of data, since you wouldn't want to blow through a million dollars of compute just to see token collapse because your contrastive loss was badly tuned. ↩
There are likely other ways to monetize "speech models for robots", including a potential B2B avenue here that would involve just selling it to other robotics companies. I don't really like this avenue because the number of potential customers seems pretty limited, the sales cycle seems like it would be high-friction and bespoke, and if they end up viewing it as a core competency they might just start building it in-house. Besides, life is too short to build B2B SaaS. ↩