Robotics Pre-training Idea
A collection of my ideas relating to robotics pre-training.
Nov 01, 2022The first step is to generate hidden units from a pre-trained image model. This should probably be done by doing k-NN on the latent space of some pre-trained model like ViT or CLIP. Potentially, the output embedding of CLIP could be used instead.
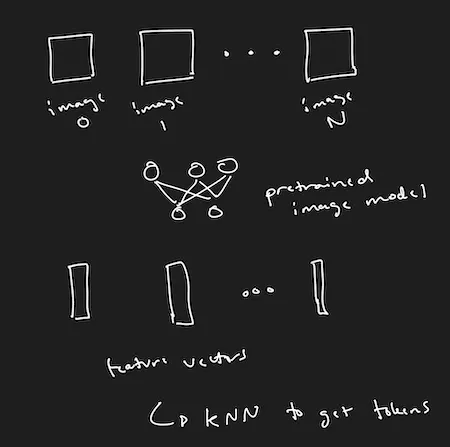
The probable problem with doing this is that the hidden units for a given clip will all be the same, or won’t capture the relevant information in the scene. For example, you could imagine a clip of a dog running through a field, and every token is something like “dog”, even though what you care about is the specific motion of the dog. Some potential ways to fix this issue:
- Subtract the average embedding over a given clip, so that the k-NN looks for features that are invariant to the average of the clip.
- Deltas from frame to frame (not sure what this would look like yet)
- Stochastic k-NN when assigning a hidden unit to an embedding - randomly sample the nearest cluster to an embedding instead of getting the nearest neighbor

Model Architecture
In this case, we likely want a forward generative model (in other words, a model which can predict the future). A few reasons for this:
- It is easier to plug into our fine-tuning workstream, since you could predict future actions rather than future states.
- When we do the next phase of pre-training, the intermediate embeddings for the model should be somehow predictive of the future; in other words, they should be modeling the evolution of the scene or some actions that are being taken. This is akin to “pseudo-actions”.
Evaluation
I had some useful conversations with various people about how to evaluate these model architectures. In particular, there are a couple ways to show the proof-of-concept:
- Run this training procedure on a toy environment, like in OpenAI gym. Record a collection of states from an environment, do action-agnostic pre-training, and see if the pre-trained representation is useful for fine-tuning.
- Given a couple of different environments this could probably be a paper in itself, if the results are interesting.
- Pre-train a big model on a bunch of video data, then do a second step of pre-training on some text-video pairs, then finally fine-tune on text-action pairs.
- This is basically only cool if it works in an actual real-world robot.